Understanding Quantization and Fine Tuning in Large Language Models
Software Engineer | Open Source Enthusiast | Mentor | Learner I love documenting stuff that I come across and find interesting. Hoping that you will love reading it and get to know something new :)
Large language models (LLMs) such as GPT, LLaMA, and Falcon have billions of parameters. While these models are powerful, their size makes them challenging to run and adapt for specific use cases. Three key concepts help solve this problem: quantization, fine-tuning, and LoRA (Low-Rank Adaptation). When combined, they make it possible to use and adapt very large models on much smaller hardware.
What is Quantization?
Quantization is the process of reducing the numerical precision of a model’s weights and activations. Most models are trained using 32-bit floating-point numbers (FP32). This provides high precision but consumes a large amount of memory.
For example, a model with 65 billion parameters in FP32 requires about 260 GB just to store the weights. That is far too large for most hardware setups.
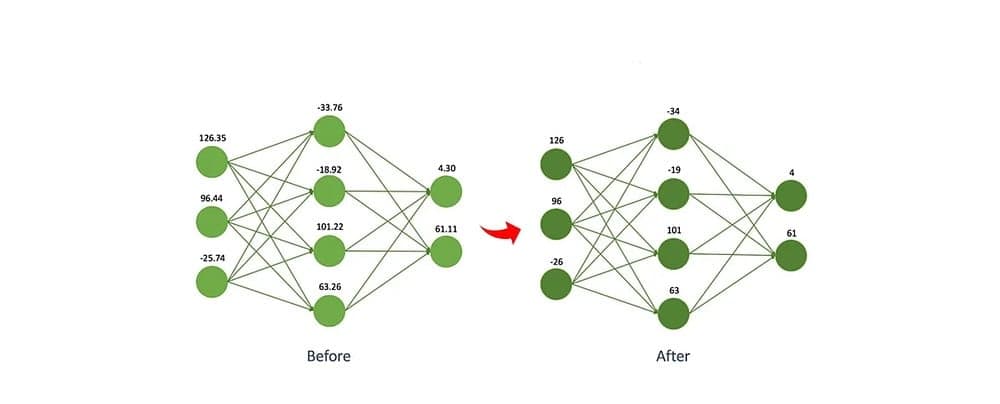
By converting weights to lower precision formats, such as 8-bit integers (INT8) or even 4-bit integers (INT4), the memory requirements drop drastically. The same 65B model in 4-bit precision takes about 32.5 GB, which can fit on a single high-end GPU.
Example: Instead of storing weights as 32-bit floats (FP32), you store them as 8-bit integers (INT8) or even 4-bit.
Why we need to reduce precision (FP32 → INT8/INT4)
Memory savings
A large model like LLaMA-65B has ~65 billion parameters.
In FP32, each weight takes 4 bytes, so:
65B × 4bytes ≈ 260GB just for weights!That’s impossible to fit on most GPUs.
But in INT4, each weight takes 0.5 bytes, so:
65B × 0.5bytes ≈ 32.5GBSuddenly, it fits on a single high-end GPU.
Speed improvements
GPUs/TPUs can process lower-precision integers much faster than full 32-bit floats.
This means lower latency and higher throughput when generating text.
Energy efficiency
Less memory traffic → less power consumption.
Important for serving large models at scale (like on Quora, ChatGPT, or Hugging Face).
But why not always use INT4/INT8?
Lower precision means less accuracy (rounding errors accumulate).
That’s why techniques like quantization-aware training or QLoRA are used → to preserve most of the model’s performance even at low precision.
We need quantization (FP32 → INT8/INT4) because without it, modern LLMs wouldn’t even fit into memory, let alone run fast enough for real use.
In addition to reducing memory usage, quantization improves inference speed and lowers energy consumption. The trade-off is a small loss in accuracy because lower-precision numbers cannot represent values as precisely as FP32. Techniques such as quantization-aware training and QLoRA are designed to minimize this loss.
What is Fine-Tuning?
Fine-tuning is the process of taking a large pretrained model and adapting it to a more specific task or domain. A pretrained model might know general patterns of language, but fine-tuning allows it to perform better in specialized areas, such as legal analysis, medical text understanding, or customer service conversations.
Without fine-tuning, the model’s performance on specialized tasks is often suboptimal. With fine-tuning, it learns domain-specific patterns from smaller datasets while retaining the broad knowledge it gained during pretraining.
What is LoRA?
LoRA, or Low-Rank Adaptation, is a method that makes fine-tuning large models more efficient. Instead of updating all of a model’s parameters, LoRA inserts small trainable matrices into specific layers of the model. During fine-tuning, only these small matrices are updated, while the original model weights remain frozen.
This drastically reduces the number of parameters that need to be trained, which in turn reduces memory requirements, compute needs, and time. LoRA makes fine-tuning feasible even on consumer-grade GPUs.
Combining Quantization and LoRA
Quantization and LoRA can be combined into a method often referred to as QLoRA. This approach loads the large model in a quantized format (for example, 4-bit) so it fits into available hardware. LoRA adapters are then added and fine-tuned on the target dataset.
The base model stays frozen, so the quantized weights are not retrained. Instead, only the lightweight LoRA parameters are updated. This approach allows researchers and practitioners to fine-tune models with tens of billions of parameters on hardware as modest as a single GPU, without losing much accuracy.
Why We Need These Techniques
Large language models are simply too big to be deployed or adapted directly in their original FP32 form. Quantization is necessary to make them fit into memory and run fast enough for real applications. Fine-tuning is necessary to adapt general-purpose models to domain-specific tasks. LoRA is necessary to make that fine-tuning efficient and affordable.
When combined, these techniques democratize access to large models. Instead of requiring hundreds of gigabytes of memory and clusters of GPUs, developers can fine-tune and deploy powerful models with far fewer resources.
👋 Enjoyed this blog?
Reach out in the comments below or on LinkedIn to let me know what you think of it.
For more updates, do follow me here :)