Understanding AI Models
Software Engineer | Open Source Enthusiast | Mentor | Learner I love documenting stuff that I come across and find interesting. Hoping that you will love reading it and get to know something new :)
Artificial Intelligence (AI) models, especially large language models (LLMs) like GPT, Claude, or Gemini, have transformed how we interact with computers. Yet, terms like tokens, token limits, quotas, tokenizers, and parameters can seem confusing at first. This blog explains these concepts clearly connecting the dots from basic text processing to complex multi-model AI systems.
What is a Token?
When you type a sentence to an AI model, it doesn’t understand it as whole words or letters. Instead, it breaks the text into small chunks called tokens. A token can be a single character, a few letters, or a complete word, depending on how often that pattern appears in human language.
Example:
| Text | Tokens (approximate) |
| “ChatGPT is great!” | [“Chat”, “G”, “PT”, “ is”, “ great”, “!”] |
That sentence becomes 6 tokens. Some models may treat it slightly differently, but the general idea remains, tokens are the building blocks of how AI reads and generates text.
Tokens are crucial because every interaction with the model consumes tokens, both for what you send (input) and what the model replies (output).
What is a Tokenizer?
A tokenizer is the algorithm or process that splits text into tokens and converts them into numerical codes that the model can process.
Language models work with numbers, not raw text. So before processing your prompt, the tokenizer:
Splits the text into chunks (tokens).
Maps each token to a unique numeric ID based on a dictionary the model learned during training.
Feeds this numeric sequence into the model for processing.
Example:
Text: “I love pizza”
Tokenizer output: [100, 451, 982]
Each number represents one token in the model’s internal vocabulary. When generating text, the model predicts the next token’s number, which the tokenizer later converts back to words.
Tokenizers are essential because they ensure consistency, the same word always maps to the same token ID. They also help manage how efficiently text is represented. Better tokenizers mean more compact and faster model processing.
Token Limits: The Context Window
Each AI model has a token limit, also called a context window. It defines how many tokens the model can handle in a single request or conversation.
For instance:
GPT-3.5 might have a 16,000-token limit.
GPT-4-Turbo might have 128,000 tokens.
Some smaller models might only handle 4,000 tokens.
This means the total number of tokens from your input plus the model’s output cannot exceed that limit.
If you go beyond it, the model either:
Truncates older parts of the conversation, or
Refuses to process the input.
Why this matters:
Larger token limits allow the model to remember longer conversations, documents, or codebases, making responses more contextually aware.
Token Quotas and Usage
A token quota is the total number of tokens you can use within a given plan or subscription. Each interaction consumes tokens from this quota.
For example:
| Plan | Monthly Quota | Usage Example |
| Free | 20,000 tokens | About 25–30 medium responses |
| Pro | 2 million tokens | Suitable for developers or researchers |
Each prompt and reply deducts tokens like this:
Tokens used = Input tokens + Output tokens
Remaining quota = Monthly quota - Tokens used
When your quota is exhausted, you must either upgrade or wait for it to reset.
Token Accumulation in Conversations
In chat-based systems, the model needs to remember previous messages for context. Each time you send a new message, the model reprocesses the entire conversation history (up to its limit).
This means token usage increases with each turn, even if your new message is short.
Example:
| Step | User Message | Total Tokens Processed |
| 1 | “Explain black holes.” | 15 |
| 2 | “Compare them with neutron stars.” | 45 (includes previous chat) |
| 3 | “Now make it simpler.” | 75 (all history included) |
This pattern is sometimes called token accumulation. It makes long conversations costlier because each response includes the previous context again.
Why Token Management Matters?
Tokens determine:
Cost: More tokens mean higher computational usage.
Speed: Larger inputs take longer to process.
Context Quality: Proper token budgeting ensures important information isn’t cut off.
Good AI applications manage tokens carefully, summarizing older context, keeping only relevant messages, and reusing previous outputs efficiently.
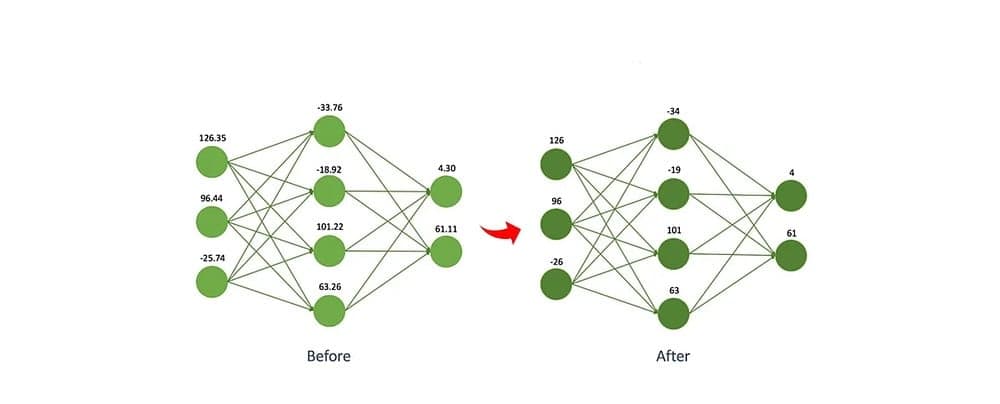
Model Parameters: The Brain of AI
Parameters are the internal settings of an AI model, the “weights” that define how it understands and generates text.
Each parameter is a small numeric value that the model adjusts during training. Together, these parameters form the network’s “memory” of language.
Example:
| Model | Number of Parameters |
| GPT-2 | 1.5 billion |
| GPT-3 | 175 billion |
| GPT-4 (estimated) | Trillions |
Parameters help the model learn:
Grammar and vocabulary patterns
Logical reasoning
Contextual associations
Emotional or stylistic tones
In short, more parameters generally mean the model can represent more complex relationships — though it also requires far more computational power.
Multi-Model Aggregators: Combining AI Systems
A multi-model aggregator is a platform or system that allows users to interact with multiple AI models through a single interface.
Instead of choosing one model, these systems:
Send your input to multiple models (like GPT, Claude, Gemini).
Collect responses from each.
Display them side by side or merge them into a single, improved answer.
Why it’s useful?
Different models have different strengths — some reason better, others are more creative or factual.
Comparing responses helps users judge accuracy and tone.
It saves cost and effort by centralizing access.
However, such systems must handle token usage carefully, because every additional model call multiplies token consumption.
How everything connects?
Tokenizer converts text into numerical tokens.
Tokens are the units of computation processed by the model.
Token limit defines how much text a model can “see” at once.
Token quota defines how much you can use over time.
Parameters determine how well the model understands and responds.
Multi-model aggregators combine different models for broader functionality.
Token management ensures performance and cost-efficiency in ongoing conversations.
Consider this-
Imagine you have:
Token quota: 100,000 tokens per month
Each message uses about 500 input tokens and 500 output tokens
That’s 1,000 tokens per message pair.
So you can make roughly:
100,000 ÷ 1,000 = 100 full interactions per month
If each conversation grows in length (say, 2,000 tokens per message later), your usage doubles quickly. This illustrates why efficient token handling and context summarization are key to scalable AI applications.
Conclusion
These concepts are backbone of AI and they determine how language models read, process, and generate information. Understanding these concepts makes it easier to use AI tools efficiently, design smarter applications, and appreciate the immense computation behind a simple chat window.
From tokenization to multi-model aggregation, every layer plays a role in transforming human language into machine understanding and back again.
👋 Enjoyed this blog?
Reach out in the comments below or on LinkedIn to let me know what you think of it.
For more updates, do follow me here :)